

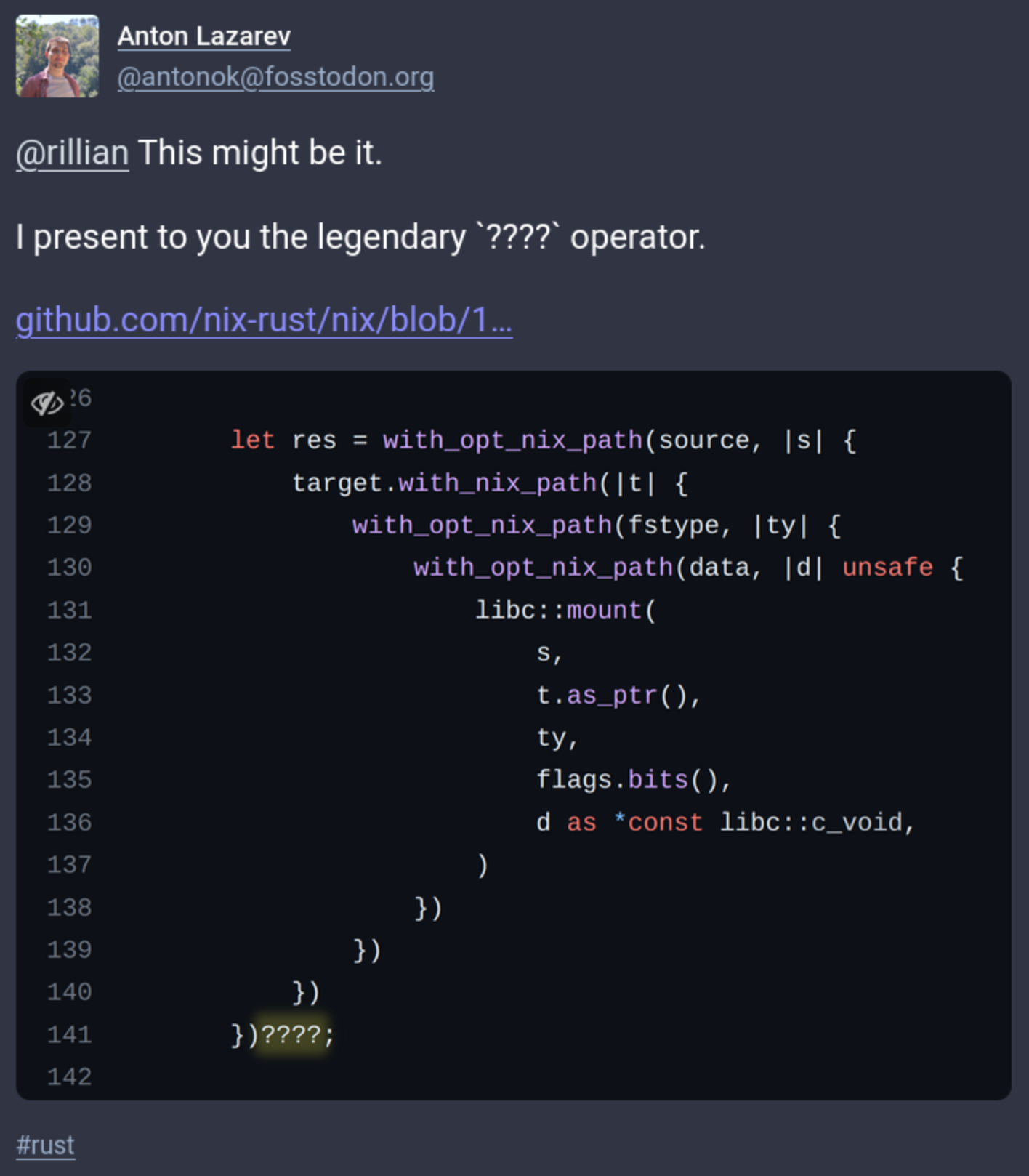
{kind=link}
I found this funny.
The context is as explained by @laund@hachyderm.io
the issue is that you can't return from inside a closure, since the closure might be called later/elsewhere
and this post was the asnwer to the question by @antonok@fosstodon.org
you got me curious what the record for the longest
?operator chain on crates.io is
Original post: https://fosstodon.org/users/antonok/statuses/111134824451525448
Is everyone genuinely liking this!
This is, IMHO, not a good style.
Isn't something like this much clearer?
// Add `as_cstr()` to `NixPath` trait first let some_or_null_cstr = |v| v.map(NixPath::as_cstr) .unwrap_or(Ok(std::ptr::null())); // `Option::or_null_cstr()` for `OptionᐸTᐳ` // where `T: NixPath` would make this even better let source_cstr = some_or_null_cstr(&source)?; let target_cstr = target.as_cstr()?; let fs_type_cstr = some_or_null_cstr(&fs_type)?; let data_cstr = some_or_null_cstr(&data)?; let res = unsafe { .. };Edit: using alternative chars to circumvent broken Lemmy sanitization.
I think the issue with this is that the code (https://docs.rs/nix/0.27.1/src/nix/lib.rs.html#297) allocates a fixed-size buffer on the stack in order to add a terminating zero to the end of the path copied into it. So it just gives you a reference into that buffer, which can't outlive the function call.
They do also have a
with_nix_path_allocatingfunction (https://docs.rs/nix/0.27.1/src/nix/lib.rs.html#332) that just gives you aCStringthat owns its buffer on the heap, so there must be some reason why they went this design. Maybe premature optimization? Maybe it actually makes a difference? 🤔They could have just returned the buffer via some wrapper that owns it and has the
as_cstrfunction on it, but that would have resulted in a copy, so I'm not sure if it would have still achieved what they are trying to achieve here. I wonder if they ran some benchmarks on all this stuff, or they're just writing what they think will be fast.