

{kind=link}
In most languages it's easy to tell where one word ends and another begins in writing, assuming that one has spacing or interpuncts or perhaps one uses some sort of logography à la Chinese or mixed script à la Japanese. But what about in speech? People will generally not make any sort of clear stop from one word to the next, in fact people will often use reduced pronunciations when they speak.
And this is why it's important to think about the methods that speakers of a language can use to separate words from each other. The process of identifying word boundaries in speech is called speech segmentation, and this process utilizes things like phonotactics and allophony, prefixes and suffixes, syntax, set or stock phrases, common contractions and reduced forms, intonation and pauses, stress and pitch accent, and simply trying to figure out the most logical interpretation of what one has just heard from the knowledge that one already has. Surely among other methods, with multiple methods working simultaneously as redundancies.
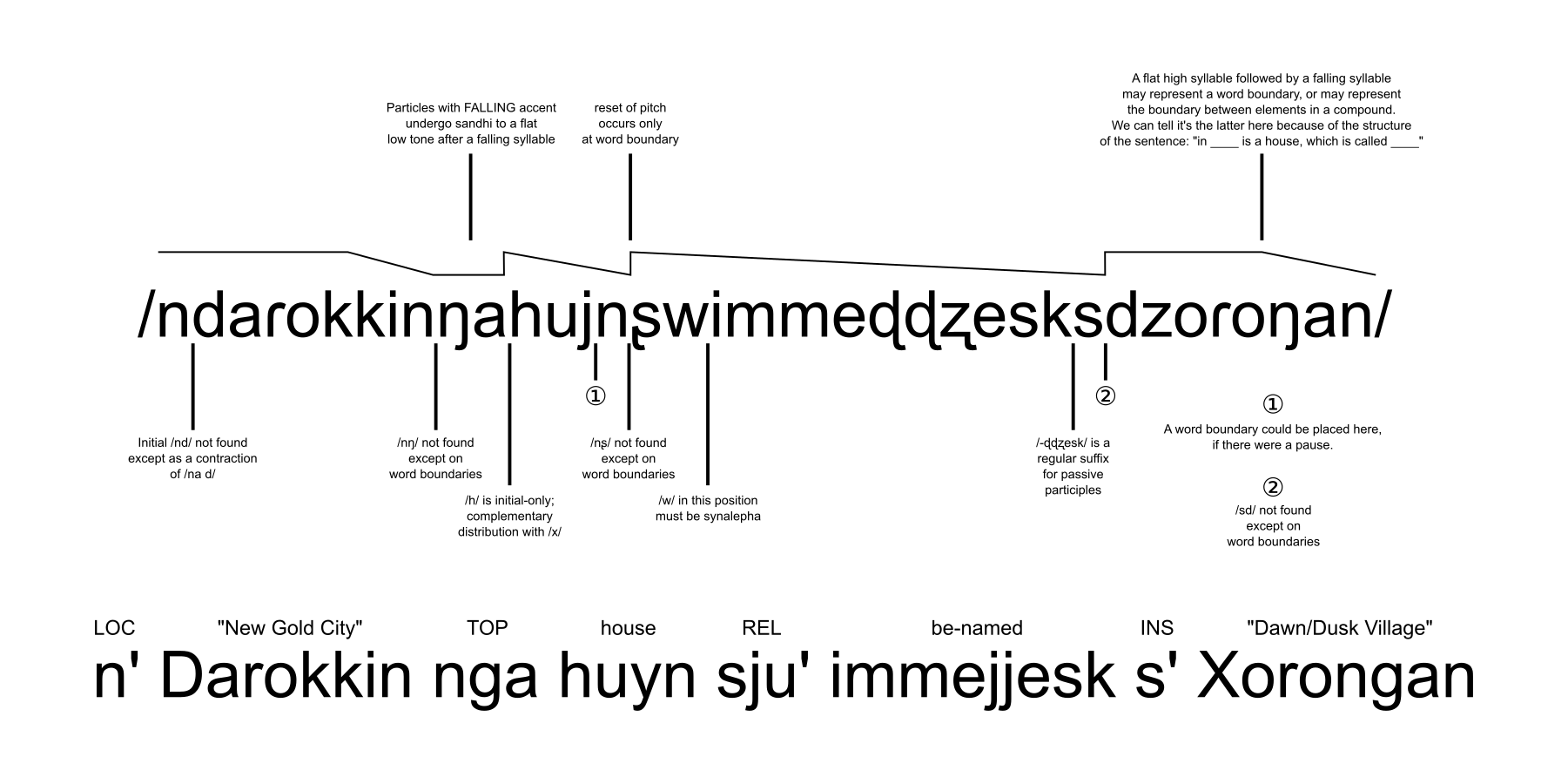
So the way I like to test this is just by writing out a sentence, and then marking down what the telltale signs are of where one word ends and another begins. I have attached a diagram of this, and I'd find it interesting to see similar charts of your own languages, or otherwise hear about the methods that your languages use.
When I say "by sound" I am assuming that you're all developing spoken languages as opposed to signed languages, but if there is anyone here who is developing a signed language, I would love to hear more about how segmentation works in such a language.
I didn't know about crisis either, thanks for the source!
What I meant is the Portuguese cacófato
One quintessential example of this is found in one famous Camoes sonnet: "Alma minha gentil que te partiste"
"Alma minha" (kind soul) sounds like "ao maminha" (to the little nipple".
Other example is: " acabou-se tudo" (all is over) Sounds like "bucetudo" (extremely vulgar way to say a person has a large vagina)
Very interesting, I'd never heard of that.