

You will go straight to jail 😡😡😡
Back during prohibition in the US, there was a product called Vine-Glo that was a brick of grape concentrate. It came with a warning: "After dissolving the brick in a gallon of water, do not place the liquid in a jug away in the cupboard for twenty days, because then it would turn into wine."
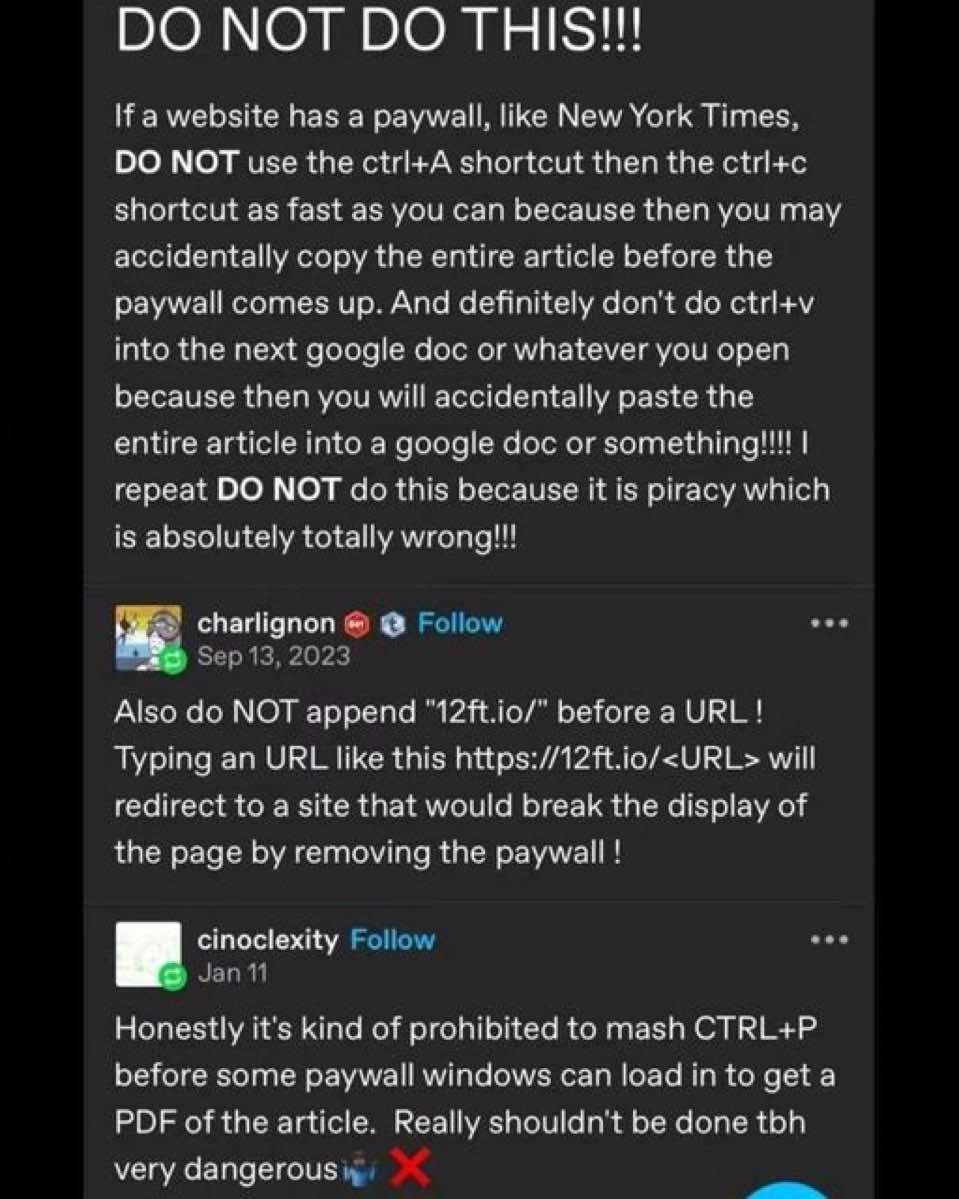
Yeah, unfortunately 12ft.io didn't keep up with the paywall arms race. It's too bad because it was one of those things that a lot of people knew about, many of whom may now just give up when it doesn't work even though there are other options out there.
As one example, there's now also the 13ft ladder: https://github.com/wasi-master/13ft It's like 12ft but self hosted. Sounds really good but I can't vouch for it yet.
I mostly would just archive a paywallrd page with archive.is (aka archive.today, archive.ph, etc.) and that worked great and also helped take traffic away from asshole sites that paywall content. Unfortunately, archive started requiring a cloud flare captcha when archiving a page. This is a deal breaker for me since captcha totally deanonymizes you and is used for tracking purposes and even to train AI. So it defeats a good chunk of the purpose of using an archive site.
Still, there's a good chance that someone else already archived the page you want to see, so putting the url in archive.is search can be enough to bypass the paywall.
Doesn't NYT cut off most of the article now? I used to just be able to disable JS but that didn't work anymore last I checked.
I use this extension and it lets me bypass pretty much every paywall including NYT's
I just hope nobody clicks the reader view button in the top right, it would be just terrible if they got an ad free, paywall free version of the site
I do that a lot on my phone but keep forgetting it's a thing on desktop for some reason.
Wow, I feel like the most upvoted solutions here don't work, and meanwhile some obvious and widely known alternatives are being completely overlooked.
❌ Inspect Element - many modern sites don't even include the full article in the paywalled html, so this wouldn't work. Also sitting there and mousing over elements and deleting them one by one, is tedious, it's easy to accidentally delete an element that encloses the content you intended to keep, or to drive yourself crazy trying to figure out how elements are nested.
❌ Ublock Zapper - a similar to the above, won't work on stub articles, and just janky because you're manually zapping things
❌ Disabled JavaScript - Similar to the above, same problem because many articles are stubs anyway. And the HTML layers that block your view don't have to be done with JavaScript.
❌ Rapid copy and paste of the article to notepad or rapidly printing the screen - similar problem to the above, lots of places just post the stub of an article, and besides nobody should live their life this way rapidly trying to print screen or copy everything. If you're trying to do a quick copy you're going to grab all kinds of gobbledygunk from the page and probably have to manually filter it out.
❌ Reader Mode - Your browsers reader mode will be hit and miss because, again, many sites post stub articles, and it's possible the pay wall stuff will just get formatted into the reader mode along with an incomplete article.
✅ Archive.is - works!
✅ Pocket and Instapaper - amazingly, nobody has mentioned these even though they're probably the longest running (dating back to 2007-2008), possibly most widely known, and most consistent solutions that still work to this day. They keep their own local caches of articles, so it's not depending on the full content being visible on the page.
✅ Other dedicated extensions - Dedicated browser extensions seem to work, but be careful what you're signing yourself up for.
🤷♀️ Brave - It works, but, it's a Chromium supported browser, so ultimately Google controls the destiny and can drive Chromium to incorporate fundamental frameworks supporting DRM and pushing their preferred web standards.
https://github.com/bpc-clone/bypass-paywalls-chrome-clean
https://github.com/bpc-clone/bypass-paywalls-firefox-clean
Many sites don't work like that and don't even load the content from the server before the paywall check.
But I have a trick that work 100% of the time. Just don't read those sites.
I get that journalism and entertainment magazines have workers and need to be paid BUT:
They were getting paid when I could pay a cheap physical newspaper if I want to read it and usually had those for free anyway. As you'll get newspapers on most public places and one single newspaper would serve a whole family. In my house we didn't really paid more than 4€ a month and got physical things that you could just keep. Now with digital distribution you own nothing and it is far more expensive. So... No. Also they get a ton of public money through institutional advertisement, so I'm already basically paying for them without getting access to their content.
So unless they are willing to change their model I'll just refuse to read them. I'm happier without their clickbaits anyway.
So unless they are willing to change their model I’ll just refuse to live.
Wait what
Saddest typo ever.
I just won't tell this to my psychologist, just in case.
DO NOT DISABLE JAVASCRIPT USING AN EXTENSIONS BECAUSE THAT WILL MAKE TRACKING STOP WORKING AND BYPASS PAYWALLS.
It will also simultaneously render the vast majority of the internet useless, and not only the shitty parts that you don't want/need anyway.
Firefox has a button that shows up in the url that kind of turns the webpage into an e-book-esque view that pops up for most articles (especially Pay Wall)
Thank you for the great advice. We should share this to a maximum of people. We don't want people to get in trouble for violating copyright especially when done accidentally.
You would never use DuckDuckGo as your default search engine and then type !archiveis in front of your urlbar visiting a news site.
One person downvoted? Are they stupid or something? Asking for a friend.






{kind=link}