Scraping enough to make a reddit clone won't make more / different requests than someone using the desktop site. Each person using the app is a different IP.
Scraping usually implies that one (or more, but usually a small number) of servers are making a large number of requests to some other website with the ultimate goal of duplicating as much of its content as possible. Something that only accesses whatever content you want to see on-demand, interactively, is not really a scraper. Yeah this reply is pendantinc weenieism, I'm sorry. Something like, idk, Invidious, is called an "alternative frontend." Point being a website can always screw with alternative frontends in various ways, including going out of business and shutting down, whereas, once the scraper has done its job, there's no screwing with it, the content is duplicated. Obviously scraping the entirety of reddit or what have you is a very dumb idea because there's a lot of garbage data that nobody will care about in 3 days time. Except for selling the data as an AI training set, no sane user would want to use that data interactively.
Bottom line is, scraping makes it so data is requested only once, and then recorded somewhere. Interactive frontends ask for the data from the source website every time someone wants to see it.

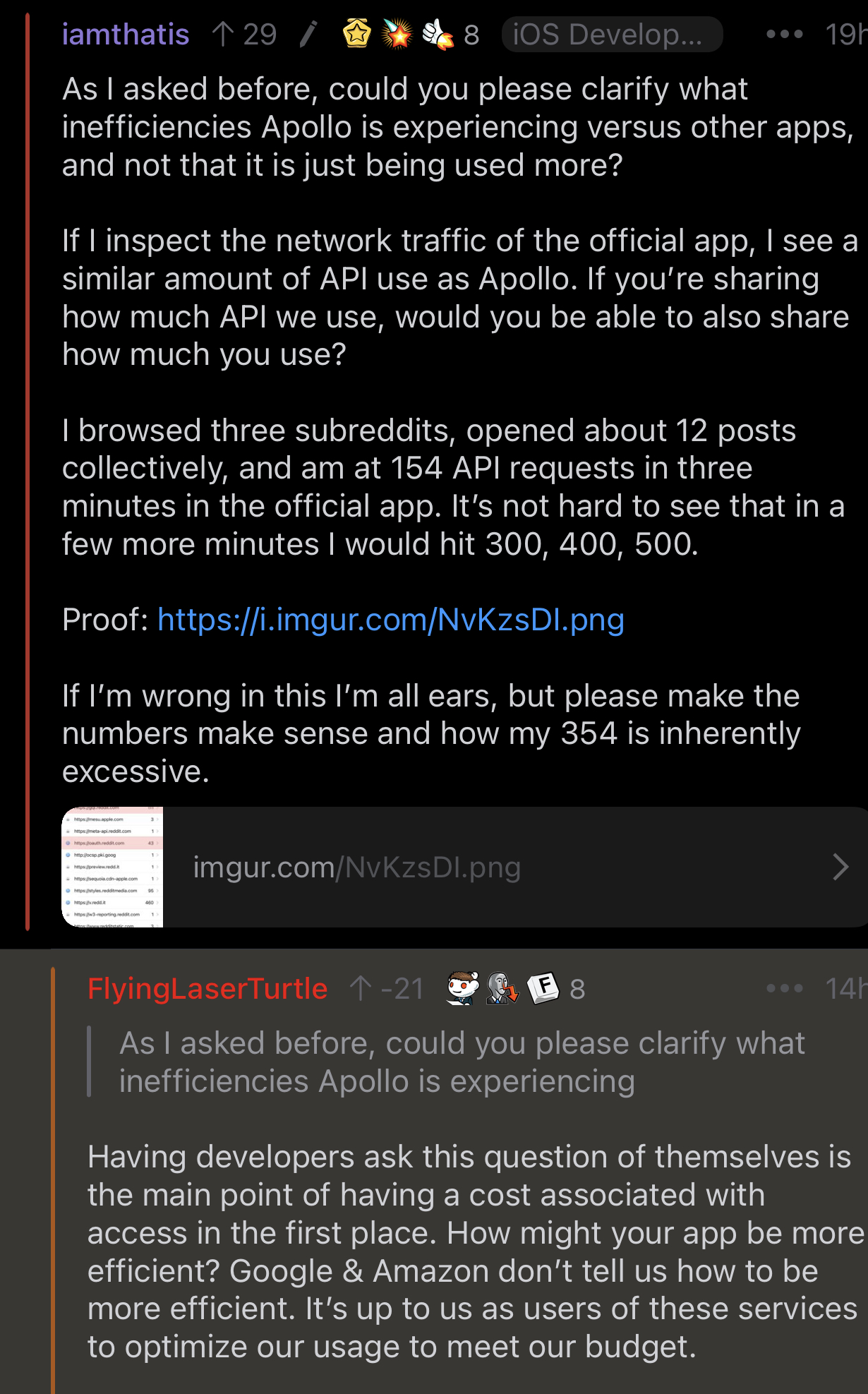{kind=link}
one could make a pretty decent reddit scraper to api script in python in like a day. im sure that will be very efficient. :sicko-hexbear:
honestly I've made things with the public reddit api, it's so bad I could almost believe a scraper is more efficient
they probably keep track of problem IPs doing that and autoban them, probably a lot of people interested in scraping reddit
botnet :)
should get me one of those at some point
Hey when the legit method is 20 million dollars that leaves a lot of room for some very well funded botnets
Scraping enough to make a reddit clone won't make more / different requests than someone using the desktop site. Each person using the app is a different IP.
Scraping usually implies that one (or more, but usually a small number) of servers are making a large number of requests to some other website with the ultimate goal of duplicating as much of its content as possible. Something that only accesses whatever content you want to see on-demand, interactively, is not really a scraper. Yeah this reply is pendantinc weenieism, I'm sorry. Something like, idk, Invidious, is called an "alternative frontend." Point being a website can always screw with alternative frontends in various ways, including going out of business and shutting down, whereas, once the scraper has done its job, there's no screwing with it, the content is duplicated. Obviously scraping the entirety of reddit or what have you is a very dumb idea because there's a lot of garbage data that nobody will care about in 3 days time. Except for selling the data as an AI training set, no sane user would want to use that data interactively.
Bottom line is, scraping makes it so data is requested only once, and then recorded somewhere. Interactive frontends ask for the data from the source website every time someone wants to see it.
deleted by creator