

https://twitter.com/TechBurritoUno/status/1768363023192768799
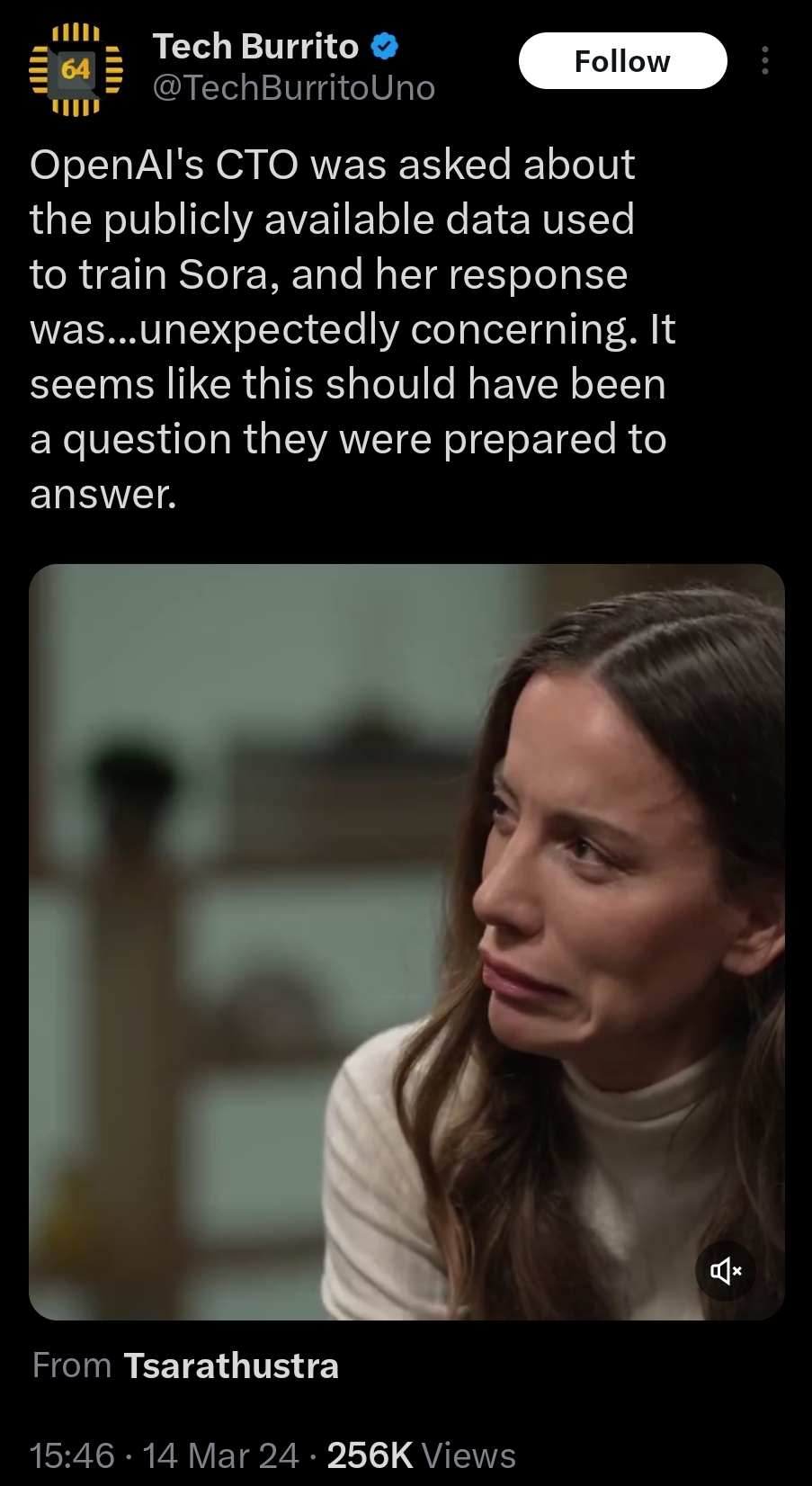
Q: "So, what data did you use to train your model?"
A: "I am sorry, my capability to answer this question is limited, as I am an AI language model. I am not privy to the inner workings of private organizations, and can only answer general questions."
I feel like it’s not that she doesn’t know the answers, it’s that the answers are not politically convenient. My understanding of the situation is that in the course of training the various GPTs, OpenAI and Microsoft have realistically scanned every piece of text and imagery that’s available on the internet. It didn’t matter how good or bad or who made it, the models needed every available data point. That was all well and good until covid led to a tightening of interest rates, which meant the VC overlords of Silicon Valley finally had to pay a bill. All the vapor ware companies that have never turned a profit are scrambling now, and we see the mass layoffs of the last three years. Microsoft, however, got to be King Shit of VC Mountain because one of their startups invented “AI”. Say what you will about it (and I will), the public interest in and corporate adoption of AI has meant that there is a positive revenue for a tech company. Now regardless of rationality, all tech executives must find a way to cash in on the Golden Calf. Some companies are designing new applications or creating new services. The majority are realizing that they some how, sort of kind of, are the original data the models were made from, and they’re trying to extract rents from it. For now, that’s really only for content in the future. If the CTO here publicly claims that their product relies on YouTube or anything, Alphabet or whatever parent would be stupid not to come and sue for whatever they might get.
The way she keeps repeating "publicly available and licensed data" makes me one hundred percent positive that this is a lawyer-written phrase and she knows that she's in a potential legal minefield and is sticking as closely to it as she can.
My quick lazy manual transcription:
What data was used to train Sora?
We used publicly available data and licensed data.So, videos on YouTube?
I'm actually not sure about that.OK, videos from Facebook? Instagram?
You know if they were publicly available, um yeah, publicly available to use there might be the data but I'm not sure. I'm not confident about it.What about Shutterstock? I know you guys have a deal with them.
I'm just not gonna go into the details of the data that was used but it was publicly available or licensed data.EDIT: Please help, can't figure out how preserve line breaks. Edit: Improved it a bit.
Two spaces on the end.
---
Yada yada verse
Yada yada verse
Yada yada verseYada yada chorus
Yada yada chorus
Yada yada chorusLemmy’s markup language is based on the CommonMark spec.
A line ending (not in a code span or HTML tag) that is preceded by two or more spaces and does not occur at the end of a block is parsed as a hard line break
They copied what reddit uses. As for why reddit does it that way - I have no idea.
 Would it be possible for the text in the box you type in to just... appear in the post exactly as you typed it?
Would it be possible for the text in the box you type in to just... appear in the post exactly as you typed it?You could wrap it in backticks:
text exactly as typedWithout the backticks, it becomes:
text exactly as typed
Edit: backticks:
``` text exactly as typed ```
I thought it was like a meme but it's literally a still from the interview. That's the CTO of OpenAI saying she's not sure what data was used to train the models lmao.
OpenAI are data goblins so the lawyers probably don't allow anyone in the C suite to know where the data comes from




{kind=link}