You can implement a sieve. I found that all 3 numbers have to be different and that you can assume that they don't share a common factor (also obviously you can assume that x<y<z so you don't have to recheck every one of the permutations), so you can skip these numbers for starters, and then you can figure out more restrictions.
It can definitely be optimized, but the point is that brute force isn't a viable option in the first place. Maybe with something GPU-based where you can stream a ludicrous number of simultaneous calculations, but I don't know if that will let you get into 80+ digit (roughly 67+ bit) values with exact precision. OpenCL caps out at 64-bit for integers, or at least used to:
(Edit: I don't know. I haven't worked with OpenCL. Me enterprise monkey. It sounds like you'd have to implement your own equivalent to BigDecimal/BigInteger around the GPU registers, which starts adding a lot of overhead for packing and unpacking your parameter triad values.)
...and then there's the problem of calculating exact-precision intermediate results. There's a reason the NSA pissed dump trucks full of money into PRISM.

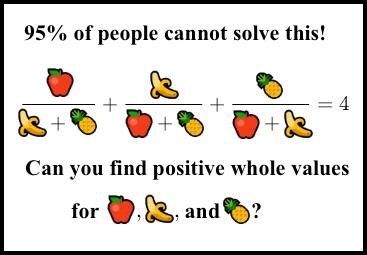
You can implement a sieve. I found that all 3 numbers have to be different and that you can assume that they don't share a common factor (also obviously you can assume that x<y<z so you don't have to recheck every one of the permutations), so you can skip these numbers for starters, and then you can figure out more restrictions.
It can definitely be optimized, but the point is that brute force isn't a viable option in the first place. Maybe with something GPU-based where you can stream a ludicrous number of simultaneous calculations, but I don't know if that will let you get into 80+ digit (roughly 67+ bit) values with exact precision. OpenCL caps out at 64-bit for integers, or at least used to:
https://stackoverflow.com/questions/6366996/work-with-128bit-or-256bit-unsigned-integers-in-opencl
(Edit: I don't know. I haven't worked with OpenCL. Me enterprise monkey. It sounds like you'd have to implement your own equivalent to BigDecimal/BigInteger around the GPU registers, which starts adding a lot of overhead for packing and unpacking your parameter triad values.)
...and then there's the problem of calculating exact-precision intermediate results. There's a reason the NSA pissed dump trucks full of money into PRISM.
Yeah idk... I've found a bunch of restrictions but it's still pretty huge...