

I would love to see a comparison of the energy, water, hardware and time that goes into this compared to just you know doing maths on a cpu like a sane person.
Capitalism truly is the most efficient system.
Well, addition is built into the instruction set of any CPU, so it only takes one operation. On the other hand, one evaluation of a neural net involves several repeated matrix-vector multiplies followed by the application of a nonlinear "activation function". Matrix-vector multiply for a square matrix will take 2020=400 multiply operations and about 2019 addition operations for a 20-dimensional input. So we'll say maybe on the order of 1,000-10,000 times more operations depending on how many layers?
This is up to 200 digit numbers, so you'd actually need to use a custom implementation for representing the integers and software addition but then a naive algorithm would still be like... 200 operations. Could probably drastically reduce that as well.
200bit numbers only require like 10 registers. X86-64 has 16 general purpose registers so doing operations with 200 digit numbers should hypothetically only require 20 loads and 10 multiplies. So a well written bit of code could do it in under 100 ops (probably under 50). So assuming this LLM implementation is running on a big server, it's probably doing the same calculation, less accurately, with some exponentially larger amount of operations.
I, as tiny little shit, was only trained up to like 7-digit addition (with far fewer examples given I suspect) and I also generalize near perfectly to 100+ digits.
I want to "train" a linear regression just to have the "models" of addition and multiplication be like x+y and exp(log(xy))
amusingly, I realized recently that I've utterly forgotten how to do long division and had to work it back out based on vague memories. now you have me wondering if I need to check addition and multiplication too... it's been... awhile... since I've had to do much beyond quick mental math in my head.
Wait, what does "near perfectly" mean? It sometimes just fucks up and arrives at the wrong answer?
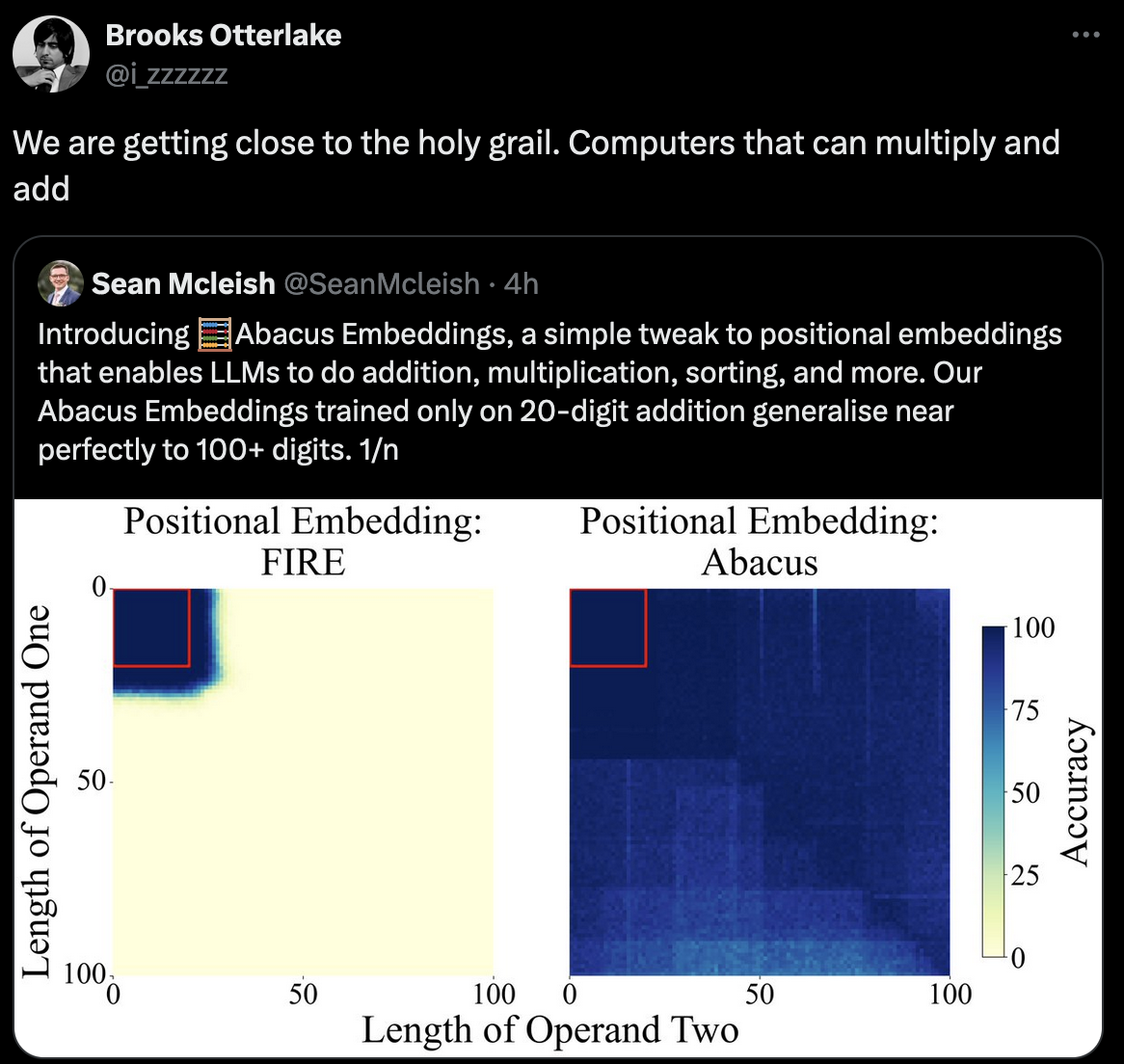
The heatmap on the right in the image shows the error. It gets progressively worse as the numbers get larger. Notably, also, the error is not symmetric in the operands, so the model is not aware that addition is commutative. Even after 2^128 or so training examples (it seems the training set is every pair of unsigned 64-bit integers) it couldn't figure out that a+b = b+a
TBH I wouldn't expect a ML algorithm to "figure out" that addition is commutative, even a good one with acceptable errors (unlike this one); it's a big logic leap that it is not really suited to get by itself (ofc this just means it is a silly way to try to do addition on a computer)
Neither would I, I guess I'm more pointing out the dustinction between prediction accuracy and understanding.
fwiw, commutativity didn't really get specifically called out by mathematicians until they adopted some kind of symbolic representation (which happened at vastly different times in different places). without algebra, there's not much reason to spell it out, even if you happen to notice the pattern, and it's even harder to prove it. (actually... it's absurdly hard to prove even with it - see the Principia Mathematica...)
these algorithms are clearly not reasoning but this isn't an example. yes, it seems obvious and simple now but it short changes how huge of a shift the switch to symbolic reasoning is in the first place. and that's setting aside whether notions like "memory" and "attention" are things these algorithms can actually do (don't get me started on how obtuse the literature is on this point).
Wait, what does "near perfectly" mean?
To save money - Boeing is already using it?
Otherwise there wouldnt be crashes.
You clearly haven’t seen my code
I think the alu messing up is something that happens quite rarely lol.
Can’t they just have an API that reaches out to wolfram alpha or something and does the math problem for them? What’s the obsession with having LLMs do arithmetic when that is not its purpose? Why reinvent the wheel instead of just us lapping on the wheels we already have?
Hi, I do AI stuff. This is what RAG is. However, its not really teaching the AI anything, technically its a whole different process that is called and injected at an opportune time. By teaching the AI more stuff, you can have it reason on more complex tasks more accurately. So teaching it how to properly reason through math problems will also help teach it how to reason through more complex tasks without hallucinating.
For example, llama3 and various Chinese models are fairly good at reasoning through long form math problems. China probably has the best math and language translation models. I'll probably be doing a q&a on here soon about qwen1.5 and discussing Xi's Governance of China.
Personally, I've found llms to be more useful for text prediction while coding, translating a language locally (notably: with qwen you can even get it to accurately translate to english creoles or regional dialects of Chinese without losing tone or intent, it makes for a fantastic chinese tutor), or writing fiction. It can be OK at summarizing stuff too.
Please tag me when you make that post. The wider community (the llm people, not hexbear) seems very negative about Chinese models and I'd be very interested in a different perspective.
Llama (acronym for Large Language Model Meta AI, and formerly stylized as LLaMA)
From Wikipedia
Even beyond arithmetic, computer algebra systems are very sophisticated. Like so much so even in the late 2000s people thought most computation would be automated. So it would totally make sense to hook up an llm to a cas. But I think the goal is to get more general reasoning out of an llm. Which, doesn't seem likely. Like the paper here is actually a pretty clever solution to an issue with llms, and it still breaks down for larger integers and as I said elsewhere, doesn't notice an important property of arithmetic
Can't wait until like idk some trains collide or buildings fall apart because an engineer used chatgpt to guess the answer to a math problem
More likely that some generated code will end up in some library that handles timing operations for rail switching and it will cause an accident and America will ban trains as a result
Since LLMs essentially decide on one character at a time, I wonder if they would have better accuracy if asked to tell you the sum backwards. That's how we teach kids to add, right to left, carry the 1.
I think this is essentially what they did. The point of the paper is they made an architecture to make the llm more aware of an individual digit's position in a number. It helped with addition, multiplication, and even sorting.
Its technically true that it decides token at a time but it also takes previous tokens into account.
That's why it's easier. if you're going left to right you have to not only figure out the sum of the first number position, but also if there's a 1 to carry or not. Going right to left you only have to focus on one 1 digit add at a time and you already know if there's a carry by looking at the last addition.
I wish the bar was set this low for anything I've ever had to program













{kind=link}