


I've found LLMs are good for code, but even then you're better off reading the docs.
Useless crap.
I have never seen an LLM be more helpful than IRC. They are, however, more polite.
i work with a bunch of former googlers and googleXers(?) and they are some of the most insufferable people on the planet
"Oh hey, do you know that the future is (grifty startup)? I can get you in on the ground floor; everyone's going to be using (grifty startup) very soon so let me hook you up to..."

they've been paid off by the electrical fire lobby
It's not that they hired the wrong people, it's that LLMs struggle with both numbers and factual accuracy. This isn't a personel issue, it's a structural issue with LLMs.
Because LLMs just basically appeared in Google search and it was not any Google employee's decision to implement them despite knowing they're bullshit generators /s
I mean, define employee. I'm sure someone with a Chief title was the one who made the decision. Everyone else gets to do it or find another job.
I work with google coders all the time, I guarantee you they were all very excited for this feature
I mean LLMs are cool to work on and a fun concept. An n dimensional regression where n is the trillions is cool. The issue is that it is cool in the same way as a grappling hook or a blockchain.
They're Rube Goldbergian machines of bullshit but the bullshit peddlers (and the glazers) insist that adding more Rube Goldbergian layers to the Rube Goldberg machines will remove the systemic problems with it instead of just hiring people to fact-check. Hatred of human workers is the point, and even when they are used, they're made as invisible as possible, so it's just a Mechanical Turk in that case.
All of this, all that wasted electricity, all that extra carbon dumped into the air, all so credulous rubes can feel like the Singularity(tm) is nigh.

Google gets around 9 billion searches per day. Human fact checking google search quick responses would be an impossible. If each fact check takes 30 seconds, you would need close to 10 million people working full time just to fact check that.
Just let them call in for answers with real people instead. Than it takes more effort and less people will do it when it's not important
Edit: also I'm pretty sure Google could hire 10 million people
also I'm pretty sure Google could hire 10 million people
Assuming minimum wage at full time, that is 36 billion a year. Google extracts 20 billion in surplus labor per year, so no, Google could not 10 million people.
Are you also suggesting it's impossible for specific times that it really matters, such as medical information?
Maybe having Rube Goldbergian machines that burn the forests and dry the lakes while providing dangerously nonsensical answers is a bad idea in the first place.
Are you also suggesting it's impossible for specific times that it really matters, such as medical information?
Firstly, how do you filter for medical information in a way that works 100% of the time. You are going to miss a lot of medical questions because NLI has countless edge cases. Secondly, you need to make sure your fact checkers are accurate, which is very hard to do. Lastly, you are still getting millions and millions of medical questions per day and you would need tens of thousands of medical fact checkers that need to be perfectly accurate. Having fact checkers will lull people into a false sense of security, which will be very bad when they inevitably get things wrong.
Firstly, how do you filter for medical information in a way that works 100% of the time
That is a good question, and it goes double for what you're apparently running interference for. How exactly does a sheer volume of bullshit justify bullshit being generated by LLMs in medical fields?
You are going to miss a lot of medical questions
Yes, and the magic of LLMs means those medical questions are going to be missed a lot more often and faster than ever before.
Having fact checkers will lull people into a false sense of security, which will be very bad when they inevitably get things wrong.
That's an amazing take: the errors aren't as bad as attempts to mitigate the flood of errors from the planet-burning bullshit machines.

If you see a note saying "This was confirmed to be correct by our well-trained human fact checkers" and one saying "[Gemini] can make mistakes. Check important info.", you are more likely to believe the first than the second. The solution here is to look at actual articles with credited authors, not to have an army of people reviewing every single medical query.
I'm still not seeing a safe or even meaningful use case for the treat printers here, especially not for the additional electricity and waste carbon costs. Were medical data queries impossible before LLMs? No, they were not.
LLM usage here doesn't help, that's true. But medical queries weren't good before LLM's either, just because it's an incredibly complex field with many edge cases. There is a reason self diagnosis is dangerous and it isn't because of technology.technology.
LLM usage here doesn't help
Yes, I'm glad we can agree on that.
The rest of what you were saying seems kind of like a pointless derail because you were defending something that's already indefensibly bad for its supposed use case here.
I feel like such a shitty engineer for not remembering or having the slightest interest in even the most basic electrical shit. i don’t even get this fucking meme.
I can do civil/mech/chem but show me electricity and I feel like I’m in preschool.
Pre 18th century ass brain capacity
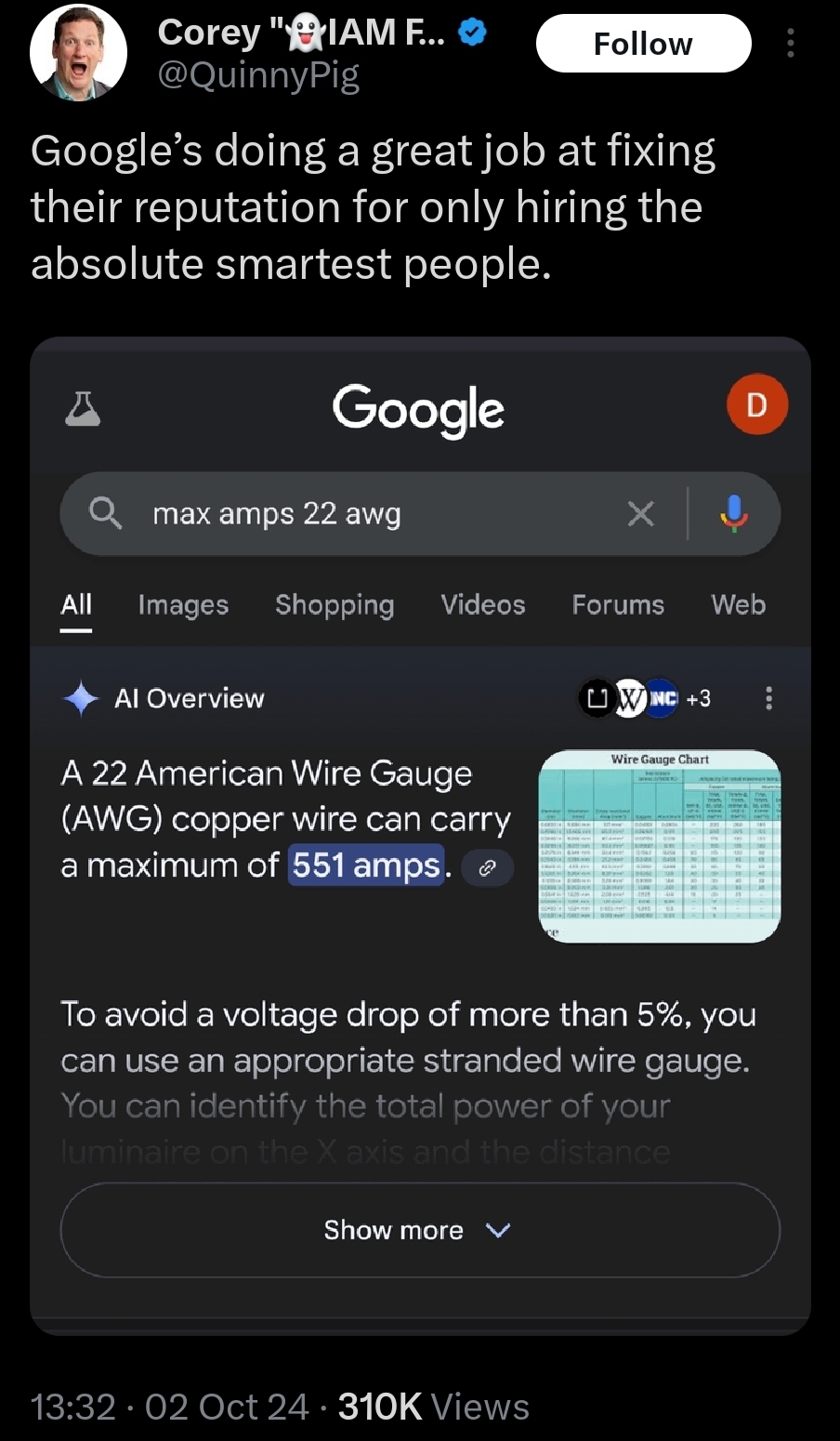
551 amps will vaporize the wire and cause Fun for all involved.
0.2 amps of current going through a human torso is fatal in virtually all cases.
North America uses 120 V for most circuits. Power is the product of voltage and current.
At 1 Amp, 120 watts are dissipated by the circuit. About the heat of two incandescent light bulbs.
At 10 Amps, 1200 watts are dissipated by the circuit, about the heat of a space heater.
At 551 Amps, 66,000 watts are dissipated by the circuit. I don't even have a good comparison. That's like the power draw of 50 homes all at once.
The higher the gauge, the lower the diameter of the wire. The lower the diameter of the wire, the more of that 66,000 watts is going to be dissipated by the wire itself instead of the load where it is desired. At 22 gauge, basically all of it will be dissipated by the wire, at least for the first fraction of a second before the wire vaporizes in a small explosion.
EDIT: In this scenario, the total resistance of the circuit must be at most 0.22 Ω. Otherwise, the current will not reach 551 A due to Ohm's Law, V=I×R. This resistance corresponds to a maximum length of 13 feet for copper wire and no load.
I ran this by my brother who’s an electrician and he inferred that might be where the number is coming from, some data on how many amps you can dump into various wire gauges before they simply stop being solids.
That’s like the power draw of 50 homes all at once.
So the average crypto mining rig?
about $75k of mining rigs actually. 66kW is a lot of heat to dissipate
The wire heats up.
Wires have a small resistance which causes a voltage drop over the wire if the current is big enough (U=RI), and therefore it draws power (P=UI) which warms it up. Thinner wires have more resistance.
Yeah, it took me a few minutes to realize "551 amps? that's an insane cartoonish number", also in the engineering field, but not electrical stuff
imagine trying to direct the output of a fire hose on full blast through one of those thin red drinking straws that come with cocktails
sort of but if we're extending the analogy i don't think the thin plastic drinking straw will make an effective replacement for the steel nozzle at the end of a water jet cutter, either
551 amps is an amount you would put in a comedic joke about using way too many amps
According to powerstream, the max amps 22 AWG can handle is 7 for chassis wiring, 0.92 for power transmission.
My job wants to use an AI medical notetaker instead of hiring someone for it... Surely nothing like this will happen :clueless:
putting the VFD into the ketchup every single time.
265k watts lol
For reference, 22awg solid is telephone wire. 22awg stranded is a hair thinner. I’ve made 22awg glow red-hot by dumping 12v and just a lil bit of anmps into it.
An enterprising lawyer is going to make a tidy sum when someone breathes copper vapor after following this advice.
I'm not sure that the kind of person who follows this advice will take enough precautions to be doing much breathing in of vapors of any kind after.
nobody who'd want to put 551 amps through jumper wire has access to a 551 amp source
I got some three phases high voltage transmission lines near my house. Going to save on my electric bill by using 22 awg to hook directly to them bypassing the meter. Cause I am bigly smart.
Just put some jumper cables on an overhead line and put into a transformer
my company is going full steam ahead with AI stuff and a coworker (who is lebanese and we talk about palestine but he has jewish cabal conspiracy
 ) loves the promise (fantasy?) of AI, especially GenAI. This mfer uses it to summarize short articles and write his emails. I feel like I'm a crazy person because I enjoy reading stuff and writing too.
) loves the promise (fantasy?) of AI, especially GenAI. This mfer uses it to summarize short articles and write his emails. I feel like I'm a crazy person because I enjoy reading stuff and writing too.He sent me a demo yesterday where they had a local instance of an LLM trained on internal data and sure enough it was able to pull info from disparate sources and it was legit kinda neat. Most of what it did was chatbot stuff but with NLP and NLG. To me, this seems like really complicated way of having a search algorithm which we know to be more efficient and faster especially since it was just fetching info.
However it was only neat bc it was running on internal data with strict boundaries, also it belies that a massive, comprehensive data dictionary had to be made and populated by people to allow for these terms/attributes/dimensions to be linked together. One of the things it did in the demo was execute SQL based off of a question
how many of these items on this date?which it then provided asselect sum(amount) from table where report_date = dateand it also provided graphs to show fluctuations in that data over time. I didn't validate the results but I would hope it wouldn't make stuff up especially since the training set was only internal. My experience with other AI apps is that you can ask the thing the same question and you'll get different results.but I would hope it wouldn't make stuff up especially since the training set was only internal
I use an internal LLM at one of the biggest tech companies and it makes shit up all the time lol
Jfc. Like who do you blame here? The model for being stupid, the prompter for not validating and if they’re validating then are there any time savings?














{kind=link}